今日《自然》重磅:迄今最大规模人类蛋白互作组诞生
来源:本站原创 日期:2020-04-10
今日,顶尖学术期刊《自然》发表了一篇重要论文:一支大型跨国科研团队发表了人类迄今为止规模最大的蛋白互作组数据,其规模是先前数据的4倍!这份蛋白互作组数据包含了约53000种不同的蛋白互作信息,无论是对理解基础的生物学进程,还是对理解疾病的发生,都有着极为重要的意义。在今天的这篇文章中,学术经纬团队也将介绍这项工作。
![▲大量研究人员参与了这项工作(图片来源:参考资料[1])](/plate/uploads/image/20200410/1586488431112015547.png)
▲大量研究人员参与了这项工作(图片来源:参考资料[1])
什么是“蛋白互作组”?
我们知道,人体由数十亿个细胞组成。在每一个细胞里,都有无数的蛋白质维持着细胞最基本的生理功能。在过去的几十年里,人们对这些蛋白质的认知已经有了长远的进步。基因组、转录组、蛋白质组数据让我们知道在不同的时间,不同的细胞内会产生哪些蛋白质。但这充其量只是一份“人口普查表”。对于这些蛋白质如何起作用,我们依然知之甚少。
蛋白互作组在一定程度上能够回答这些问题。顾名思义,这能提供大量蛋白质与蛋白质互相作用的数据。我们知道了这些蛋白质如何起作用,就能更好地理解它们的生理功能。
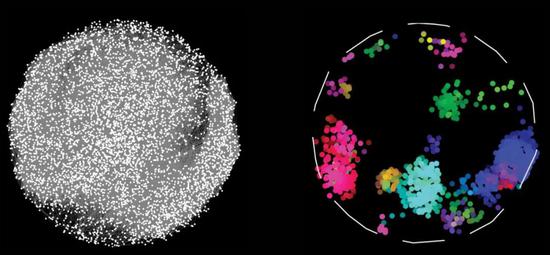 ▲科学家们分析了约17500个人类蛋白的相互作用(左图)。具有类似模式的蛋白被分为不同的组(右图)(图片来源:Katja Luck et al。)
▲科学家们分析了约17500个人类蛋白的相互作用(左图)。具有类似模式的蛋白被分为不同的组(右图)(图片来源:Katja Luck et al。)
“自上世纪90年代中期起,我们的合作团队就认为蛋白互作组能揭示生命最基础的特征,”本研究的负责人之一,丹娜-法伯癌症研究所的Marc Vidal教授说道:“我们的研究展现了首个人类蛋白互作组的参考图谱(reference map),建立了一个信息框架,让我们能更好地理解突变基因如何导致癌症等疾病。此外,我们也能知道诸如新冠病毒等病毒如何与人类宿主蛋白产生相互作用。”
十年磨一剑。在来自美国、加拿大、西班牙、比利时、法国、以及以色列的80多名科学家的共同努力下,这些重要的信息终于诞生了。
蛋白互作组是怎么做的?
要阐明蛋白之间所有的相互作用关系,并不是一件容易的事情。在这项研究里,科学家们使用了一种经典的方法——酵母双杂交。根据最新的理解,人类基因组中一共有大约17500条编码蛋白质的基因。科学家们在酵母中测试这些蛋白是否会两两发生互相作用。如果这两个蛋白的确会互相作用,就会启动特殊的分子开关,让酵母细胞开始生长。
所以,科学家们只要观察酵母细胞是否能生长,就能判断相应的两个蛋白是否会发生相互作用。
这个工作量可不小。单是测试一轮,就有3亿(17500乘以17500)多种不同的可能性。而为了实验的准确性,研究人员们使用了三种不同的酵母体系,且在每一个体系里,都将这个实验重复了3遍。这样一来,他们所做的单独测试多达约30亿个!
![▲本研究的工作量堪称巨大(图片来源:参考资料[1])](/plate/uploads/image/20200410/1586488431175036026.png)
▲本研究的工作量堪称巨大(图片来源:参考资料[1])
从这些实验的结果中,研究人员们找到了约53000个比较可信的蛋白互作,涉及到了8000多个不同的蛋白质。值得注意的是,其中大部分都是从未被发现的新型相互作用。
这项工作有什么意义?
研究人员们指出,对于大部分人类蛋白,我们还不是很清楚它们的功能。而蛋白相互作用的信息,可以让我们推测出关于蛋白功能的一些信息——如果两个不同的蛋白质都与类似的蛋白进行结合,那么它们就可能有类似的生物学功能。
“我们能利用人类蛋白互作组图谱来预测蛋白质的功能,”本研究的另一位负责人Frederick P Roth教授说道:“人们可以去检索他们感兴趣的蛋白,并根据与之结合的其他蛋白,得到一些关于其功能的线索。”
事实上,根据这项工作,研究人员们已经产生了不少洞见。譬如他们找到了一些参与程序性细胞死亡、或是释放细胞内容物等过程的蛋白。如果这些蛋白出了差错,就有可能导致疾病。
![▲该研究找到了一些组织特异的蛋白网络(图片来源:参考资料[1])](/plate/uploads/image/20200410/1586488431191003039.png)
▲该研究找到了一些组织特异的蛋白网络(图片来源:参考资料[1])
更有意思的是,如果将蛋白互作组数据和组织特异的基因表达数据联合起来看,还能发现在不同组织的发育和维持过程中,所需要的蛋白网络。我们也可以知道那些发生突变的蛋白会如何影响其作用的网络,从而导致疾病。在这些网络里,我们还可以找到不少治疗疾病的潜在靶点。
后记
正如研究人员们所言,这项工作填补了目前存在的一些空缺,将表型与基因组/蛋白组更好地连接在了一起。或许是由于酵母与人类所存在的差异,研究人员们评估,该工作可能只覆盖了2%-11%的人类蛋白互作组。但即便如此,目前的成果也已足够有用,并已吸引了超过15000人使用。将来,科学家们将使用新型技术,进一步扩大该数据库的覆盖面,以求为科学研究提供宝贵的数据。